写在前面:
本文于原csdn博客上迁移。为了记录每天的学习进度,一共分为好几篇博文,现整合成一篇博客。
打开heidisql,登陆账号,点击连接
发现里面已经创建好一个数据库了但是本着学习的精神,我认为应该自己创建一个新的数据库,于是敲击如上图中的代码
发现无法创建,,,噢,原来我们用的是中文的分号!
呜呜呜,中文英文一定要好好区分,否则你会很难受让我们再试一次
显示,access denied for user to database,啊这,我裂开了为什么会出现这种情况?
我紧接着去网上搜索了一下,应该是我没有权限导致的,然后又在界面上随便点了点左上角那个两个人头的图标弹出来一个界面
这里的reload privilege上网查了查说是administrative级别的权限,那事到如今没有权限实锤了,暂时跳过创建新的数据库这一步,就在已有数据库里面进行操作吧。
进入表data_1,全部是图形化操作界面,
如果你想要往表单里面添加新的字段,这很简单,只需要点击绿色的加号就可以了。简单是简单,但是不能直接把别人写好的脚本导入进自己的数据库里面,而且没有MySQL黑黑的命令行。
为了体验MySQL的命令行程序,特地去下载了MySQL
。。。
然后到了晚上
。。。
打开heidisql,进入一个新的数据库。
数据库里最初是没有表单的需要我们要向数据库里面create新的表单,分别是bonus,dept,emp
并且在导入表单后插入数据
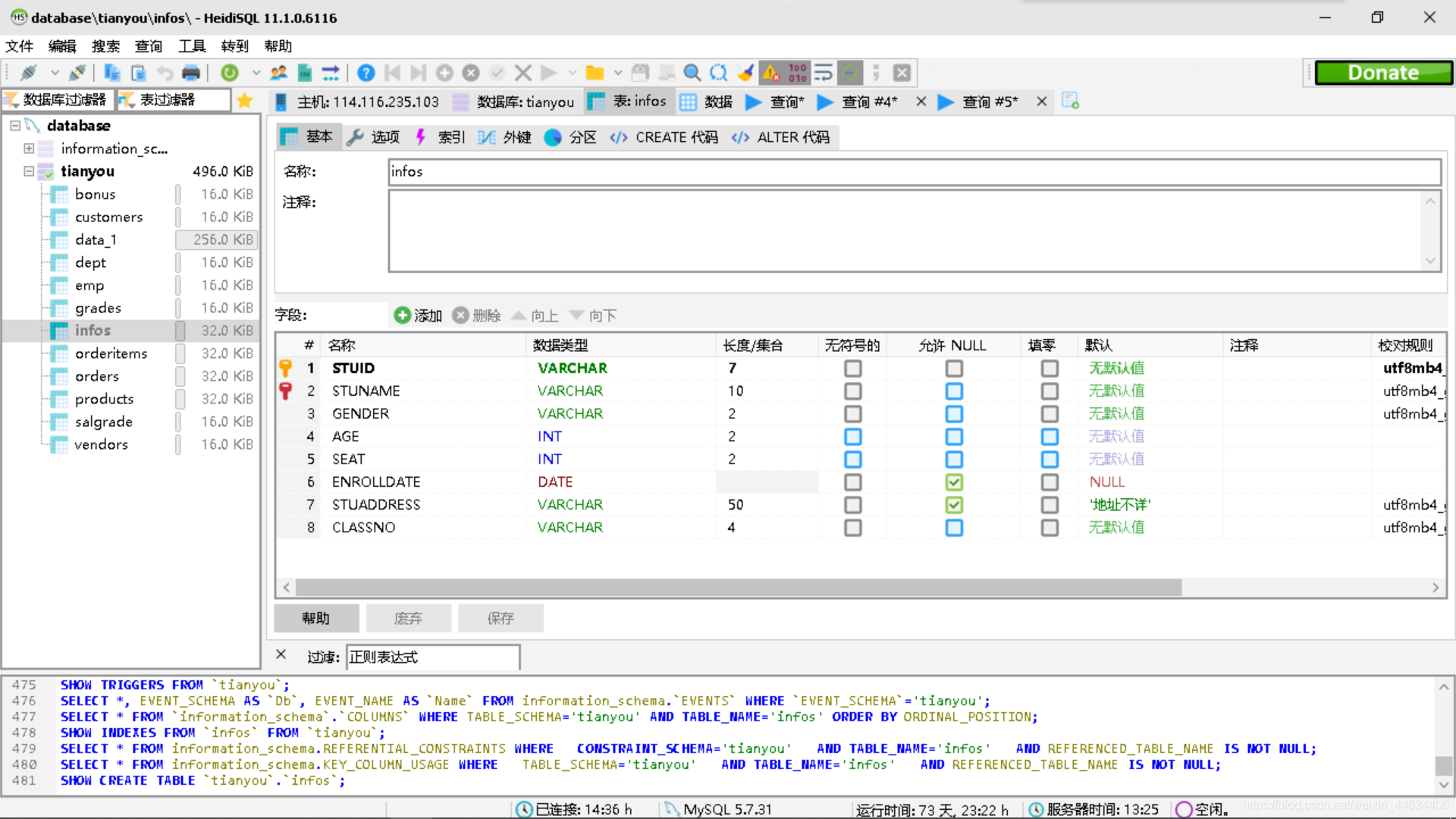
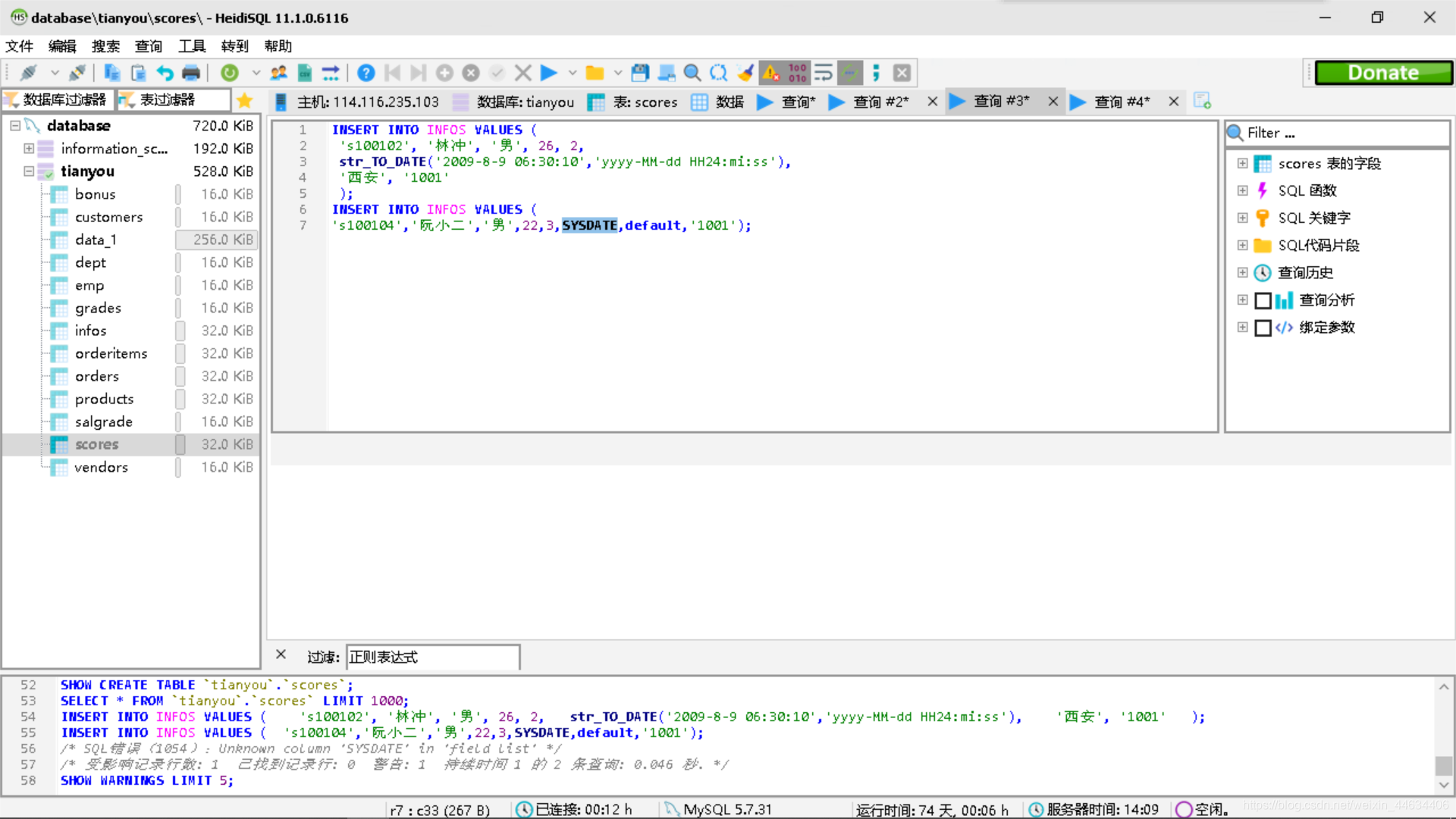
简单的查看后,数据已经被导入到表单中接着我们创建新的表单及其约束,表单名字为infos
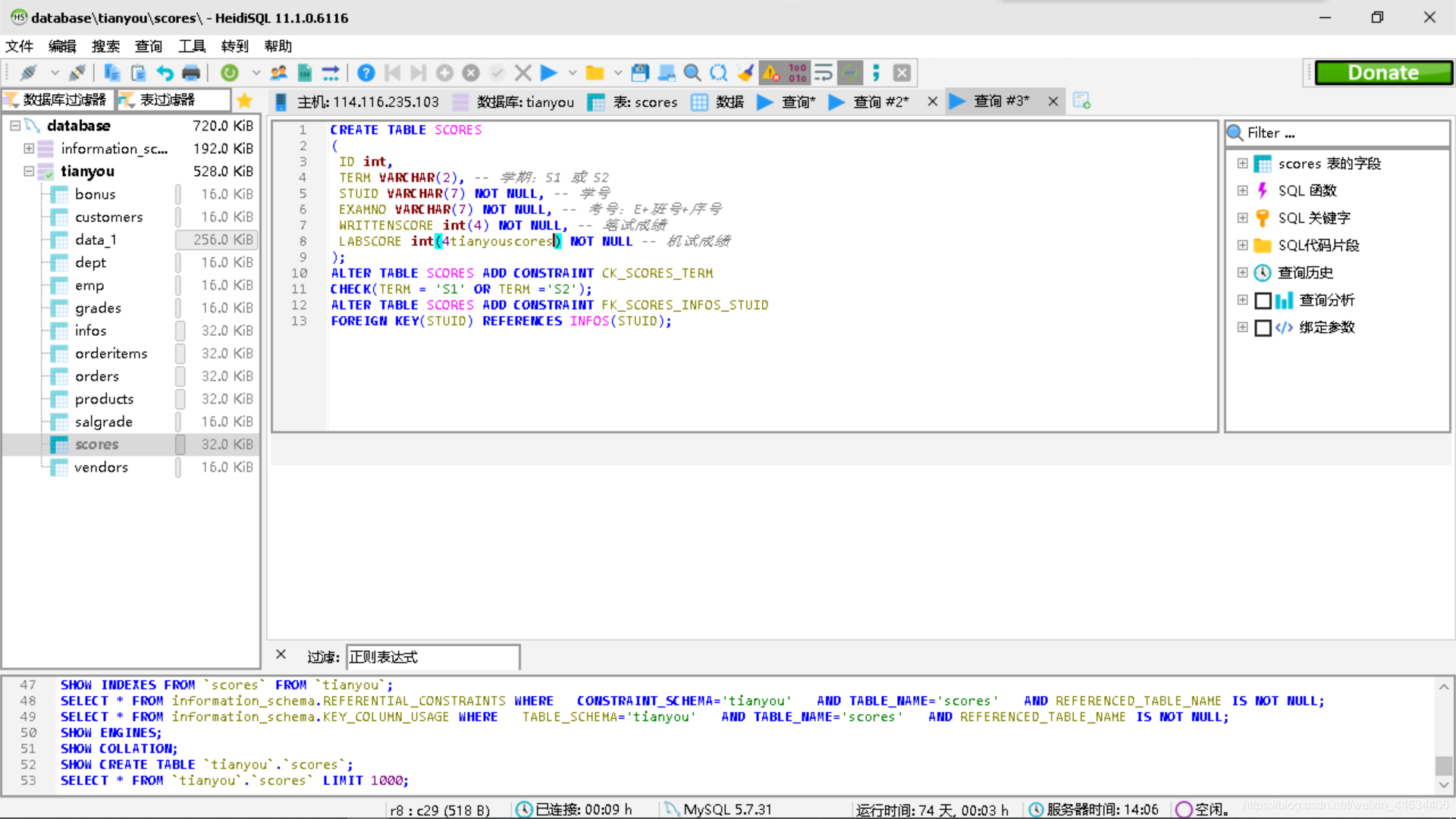
创建完成后,我们再对scores进行操作
现在表单中还没有数据,我们向表单中手动添加数据
插入数据的时候我们发现SYSDATE显示 unknown column ,上网搜了一下,这里的SYSDATE本意应该是向表单中插入一个当前时间,这个SYSDATE是Oracle的函数,在HeidiSQL相应的函数是CURDATE(),然后我们将其改成CURDATE()就成功填入表单了。
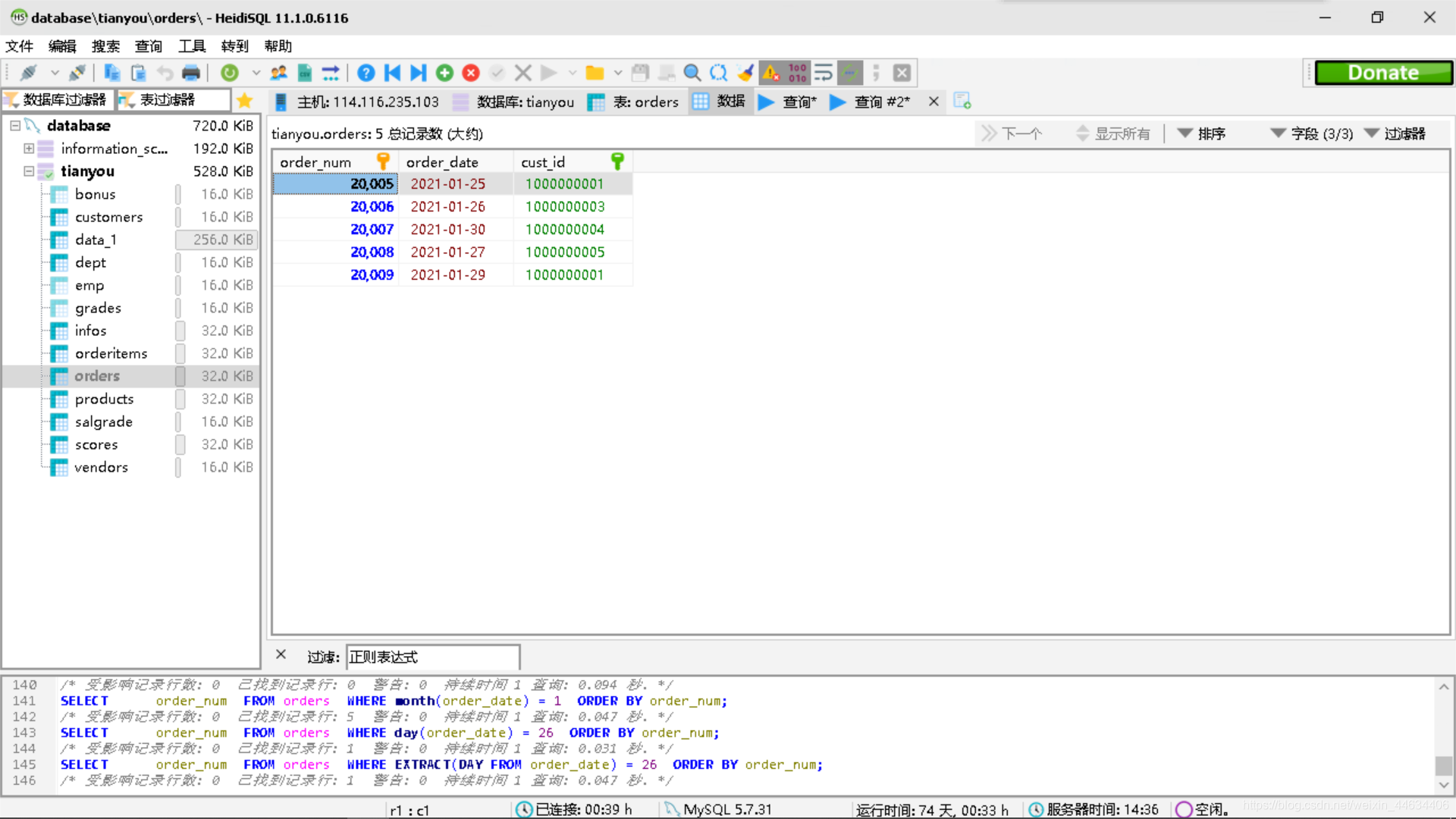
现在我们对orders这个表单进行操作
2
3
4
5
6
order_num
from orders
where year(order_date) = 2021 -- 这个里面的year()函数也可以改成
-- extract(year from order_date)
order by order_num;每个数据库里面有自己不同的函数,造成代码的可移植性很差,要根据不同的数据库选择不同的函数
拿日期来说,在Oracle里面可以用函数to_date,但是在MySQL里面只能使用str_to_date,并且后面的格式与Oracle不一样,在复制代码粘贴的时候总是遇到很多问题,需要我们一个个去手动调整
附个日期的格式,MySQL与Oracle日期格式的不同之处
1.mysql日期和字符相互转换方法
date_format(date,’%Y-%m-%d’) ————–>oracle中的to_char();
str_to_date(date,’%Y-%m-%d’) ————–>oracle中的to_date();
%Y:代表4位的年份
%y:代表2为的年份
%m:代表月, 格式为(01……12)
%c:代表月, 格式为(1……12)
%d:代表月份中的天数,格式为(00……31)
%e:代表月份中的天数, 格式为(0……31)
%H:代表小时,格式为(00……23)
%k:代表 小时,格式为(0……23)
%h: 代表小时,格式为(01……12)
%I: 代表小时,格式为(01……12)
%l :代表小时,格式为(1……12)
%i: 代表分钟, 格式为(00……59) 【只有这一个代表分钟,大写的I 不代表分钟代表小时】
%r:代表 时间,格式为12 小时(hh:mm:ss [AP]M)
%T:代表 时间,格式为24 小时(hh:mm:ss)
%S:代表 秒,格式为(00……59)
%s:代表 秒,格式为(00……59)
2.例子:
select str_to_date(‘09/01/2009’,’%m/%d/%Y’)
select str_to_date(‘20140422154706’,’%Y%m%d%H%i%s’)
select str_to_date(‘2014-04-22 15:47:06’,’%Y-%m-%d %H:%i:%s’)特别要注意的地方,这个时要区分大小写的。
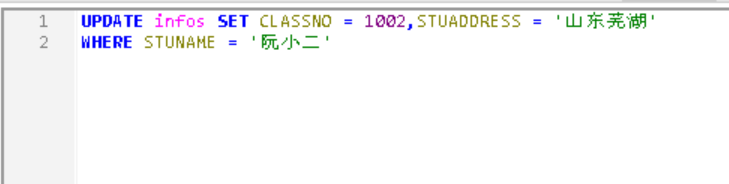
这时候发现两个问题,阮小二的地址不详,班级错误,我们怎么才能对地址和班级进行更新呢?我们可以使用 UPDATE 命令来操作。
语法:
2
[WHERE Clause]现在来演示一下
F5刷新
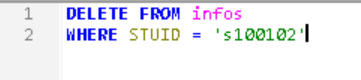
更新表单之后,林冲因为出去买酒耽误了上课,教务处做出退学处理,需要把林冲从表单上移除,怎么实现呢?可以使用delete语句
同样来实操下
现在林冲被退学了另外我们还可以利用已有的表单做些新的事情
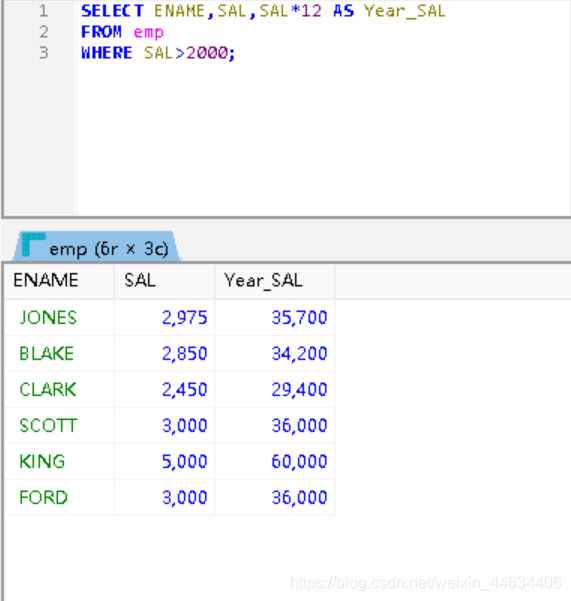
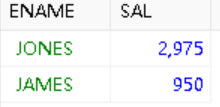
为了相应提高基本工资的号召,我们想要知道基本工资在 2000 元以上的员工姓名及其工资和不含奖金的年总工资信息,以方便统计哪些员工不需要提高工资水平。
键入以下代码
2
3
FROM emp
WHERE SAL>2000;容易得到
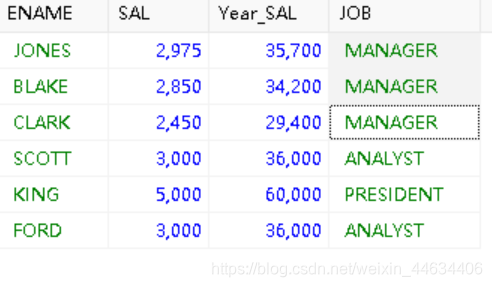
如果我们还想看看这些员工的工作都是什么,只需要在后面加上JOB
大部分都是manager接下来,我们还可以
查询 EMP 表中的员工所在部门编号;
查询出薪酬少于 2000 且没有发奖金的员工
查询工作职责是 SALESMAN、PRESIDENT 或 ANALYST 的员工
查询工资从 1000 到 2000 之间的员工
查询员工名称以 J 开头以 S 结尾的员工的姓名、工资和工资
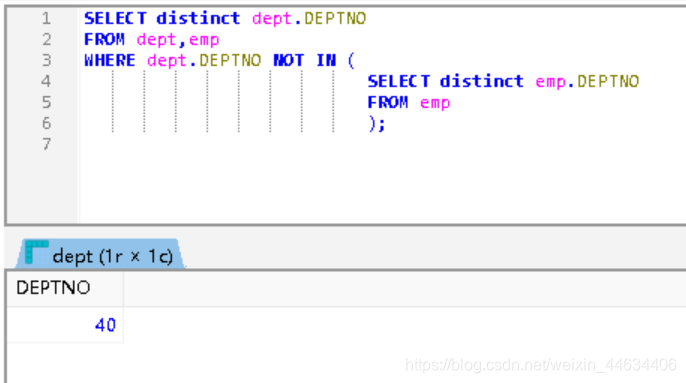
查询出 DEPT 表中没有员工的部门编号
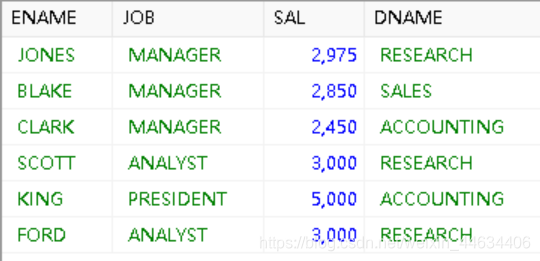
查询出月工资大于 2000 元的员工姓名、工作、工资,及其所在部门名称
前几个问题的解决比较简单,只需要在一个表里面就可以实现,所以把代码贴在一起
2
3
4
5
6
7
8
9
10
11
12
13
14
FROM emp;
SELECT ENAME
FROM emp
WHERE SAL<2000 AND COMM is NULL;
SELECT ENAME
FROM emp
WHERE JOB = 'SALESMAN' OR 'PRESIDENT' OR 'ANALYST';
SELECT ENAME
FROM emp
WHERE SAL BETWEEN 1000 AND 2000;
SELECT ENAME,SAL
FROM emp
WHERE ENAME LIKE 'J%S';结果如图
最后两个问题单独列出来
2
3
4
5
6
FROM dept,emp
WHERE dept.DEPTNO NOT IN (
SELECT distinct emp.DEPTNO
FROM emp
);
以及
2
3
FROM emp,dept
WHERE emp.SAL>2000 AND emp.DEPTNO = dept.DEPTNO;
下面还有几个问题
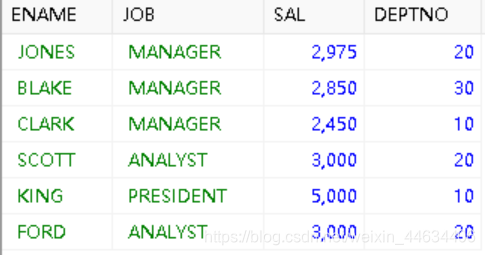
1、查询出工作职责不是 SALESMAN、PRESIDENT 或 ANALYST 的员工姓名、工作、工资,及其所在部门名称。
2
3
4
FROM emp,dept
WHERE emp.SAL>2000 AND emp.DEPTNO = dept.DEPTNO
AND (JOB NOT IN ('SALESMAN' , 'PRESIDENT' ,'ANALYST'))
2、换一种方法查询出工资大于 2000 元的员工姓名、工作、工资,及其所在部门名称。
2
3
4
FROM emp,dept
WHERE SAL > 2000 AND emp.DEPTNO = dept.DEPTNO
ORDER BY EMPNO;
3、查询出每个部门下的员工姓名和工资。
2
3
4
FROM emp,dept
WHERE emp.DEPTNO = dept.DEPTNO
ORDER BY emp.DEPTNO;
4、如果在步骤 2.4 中使用 sys 用户查询学生用户的 INFOS 表,能否查询到学生
用户 INFOS 表的添加、删除、修改操作?为什么?如果不同,如何才能让 sys 用
户查询到学生用户对 INFOS 表的添加、删除、修改操作?
先简要贴个表,记录select子句及其顺序| 子句 | 说明 |
|-- |–|–|
| select | 要返回的列或者表达式 |
|from |从中检索数据的表
|where|行级过滤
|group by|分组说明
|having|组级过滤
|order by|输出排序顺序
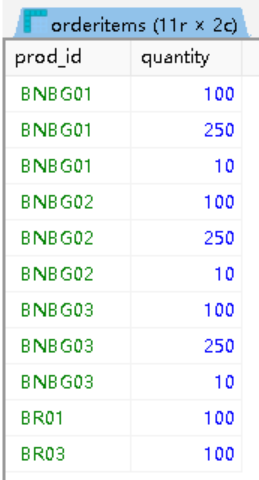
在数据库里面已经安排好了orderitems表单
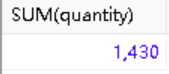
-------------------------------------------------------------------------------- 确定已售出产品的总数
2
FROM orderitems;输出得到
我们还可以对上面的列名重新命名
2
FROM orderitems;在select句后面加上as
很简单的可以实现列名的修改
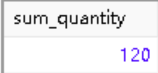
对刚刚创建的语句进行一个小学二年级程度的修改,可以实现确定已售出产品项BR01的总数
2
3
FROM orderitems
WHERE prod_id = 'BR01';and we get
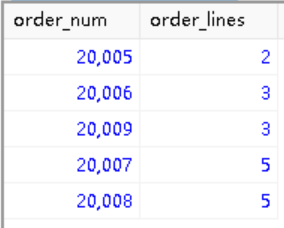
------------------------------------------------------------------------------------ 下面进阶一小点,加上group by 确定每个订单号有多少行数,并且按照行数对订单号排序
2
3
4
FROM orderitems
GROUP BY order_num
ORDER BY order_lines;
------------------------------------------------------------------ 再次进阶一点,子查询 返回购买prod_id为BR01的所有顾客的电子邮件 先附上语句
2
3
4
5
6
7
8
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN ( SELECT order_num
FROM orderitems
WHERE prod_id = 'BR01')
ORDER BY order_date);
信息记录: 逆序排列语句ok
子查询
现在我们需要查询一个顾客列表,里面包含已订购的总金额(返回顾客ID,顾客订单总数,结果按照金额从大到小排序)
2
3
4
5
6
7
8
9
10
11
12
COUNT(*) AS total_order,
(select SUM(quantity*item_price)
FROM orderitems
WHERE orderitems.order_num = orders.order_num)
AS total_value
FROM orders
GROUP BY cust_id
ORDER BY (SELECT SUM(quantity*item_price)
FROM orderitems
WHERE orderitems.order_num = orders.order_num
GROUP BY orderitems.order_num) desc;这些语句实现了好几件事情
首先是从orders表中返回cust_id和每个id一共下单次数,同时还把每个id的订单总金额显示在最后一列。
排序按照订单总金额从大到小降序排列。
联结内联结
2
3
4
5
vend_name,
prod_name
FROM vendors
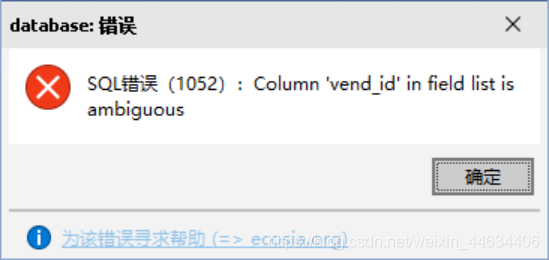
INNER JOIN products ON vendors.vend_id = products.vend_id;尝试多表查询
很遗憾程序出错
网上声称出现这种问题,是没有具体声明参数在哪个表单中。Σ(っ °Д °;)っ
检查发现select子句中的vend_id,因为其同时存在于在vendors和products两个表中,所以我们需要在前面加上表头。
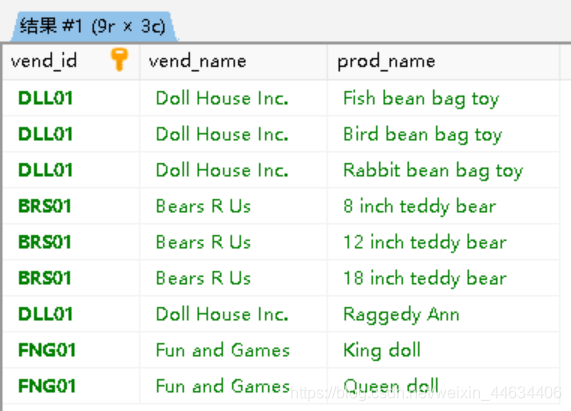
再贴一次语句
2
3
4
5
vend_name,
prod_name
FROM vendors
INNER JOIN products ON vendors.vend_id = products.vend_id;好耶!!!这次一切正常!!!
如果我们想一次性联结多个表单有应该怎么做呢?方法一:用where······and······and·····
方法二:用inner join···on····inner·····join···on···
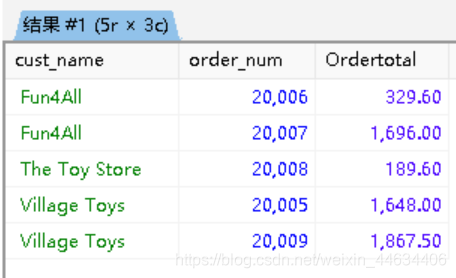
2
3
4
5
6
7
8
9
10
11
order_num,
(SELECT SUM(quantity*item_price)
FROM orderitems
WHERE orderitems.order_num = orders.order_num
)AS Ordertotal
FROM customers
inner JOIN orders ON orders.cust_id = customers.cust_id
ORDER BY cust_name,
order_num
;上述语句在一次查询中同时使用了子查询和内联结
返回顾客名称、订单号、以及每个订单的总金额
创建高级联结
自然联结 排除多次出现的列,让每列值出现一次,而这个排除工作由你自己来完成。
外联结,左外联结和右外联结
**外联结** 两种基本的外联结形式,左外联结和右外联结 在简单的联结两个表时,我们只需要使用两个表中的公用字段 另外一种外联结,全外联结左外联结
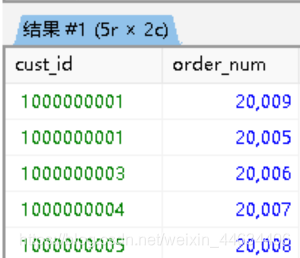
我们已经知道,如果我们想显示所有订单编号,以及其对应的顾客id,我么可以直接用内联结来实现
2
3
4
5
orders.order_num
FROM customers,orders
WHERE customers.cust_id = orders.cust_id
ORDER BY customers.cust_id;实现结果如下
我们明显可以发现在cust_id这里,我们缺少了没有下过订单的顾客如果我们想显示在orders表中值为null的顾客,我们需要怎么做呢?
这个时候,我们需要使用外联结
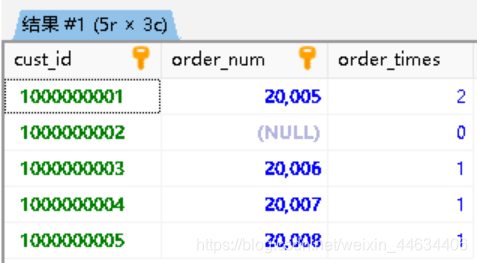
2
3
4
5
6
orders.order_num,
COUNT(order_num) AS order_times
FROM customers
LEFT OUTER JOIN orders ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id;这段代码和上面的有什么不同之处呢?
关键字LEFT OUTER JOIN实现了工作关联两个表中没有关联行的的那些行
customers表中的某位cust从未下过订单,因此在orders表中就没有这位cust的数据,内联无法将这两个表中两行不关联的信息关联起来
但是使用外联结就可以
我们使用LEFT指定一个在包括其所有行的表单
在orders表中没有的值,在结果中自动添加上null值代替
同时我们还在语句中加入聚集函数,统计每个cust的下单总数
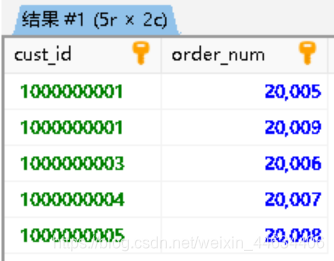
同理,我们也可以使用右外联结
2
3
4
orders.order_num
FROM customers
RIGHT OUTER JOIN orders ON customers.cust_id = orders.cust_id;输出
左外联结和右外联结之间唯一的区别是做关联的表的顺序。或者说,调整from子句和where子句在表中的顺序,左外联结就可以转换成右外联结
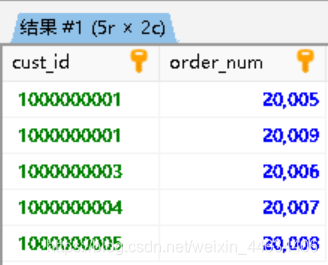
我们来试一下把右外联结变成左外联结
2
3
4
5
orders.order_num
FROM orders
LEFT OUTER JOIN customers ON orders.cust_id = customers.cust_id
;他们的输出是一模一样的
知识记录:在哪里判断左右?
right指的是在outer join右边的表
left值得是在outer join左边的表
ATTENTION!
总是需要提供联结条件否则会出现笛卡尔积组合查询
UNION关键字一些小规则
使用union必须由两条及其以上的select语句组成,语句之间用关键字union分隔
union的每个查询必须包含相同的列、表达式或者是聚集函数
列数据的类型必须兼容
ATTENTION
如果结果中由重复的行,在union后将彼此合并,只返回一行如果我们想要将查询到的所有行一五一十全部返回,这个时候我们又应该怎么做呢?
UNION ALL关键字,它可以让数据库返回查询到的所有行,而不消去重复的行
下面是一个生动的例子
将两个select语句结合起来,一边从orderitems中检索出产品prod_id和quantity。其中,一个select语句过滤数量为100的行,另一个select语句过滤ID以BNBG开头的产品。按产品ID对结果进行排序。
2
3
4
5
6
7
8
9
10
quantity
FROM orderitems
WHERE quantity = 100
UNION
SELECT prod_id,
quantity
FROM orderitems
WHERE prod_id LIKE 'BNBG%'
ORDER BY prod_id;上述语句用在where子句处做修改也可以实现相同的功能
特别需要注意的是,在对union结果进行排序时,能且只能在union的最后一条select语句中进行order by
如果在多条select语句中进行order by ,查询将会报错插入数据
简单的记录下格式
2
3
4
values(value1,
value2,
value3);
2
3
4
5
6
7
8
cust_name,
cust_address,
cust_city)
VALUES('1000000007',
'Alice',
'qingyang road 3nd',
'chengdu');更加安全的格式是
2
3
4
5
6
7
8
col2,
col3,
col4)
values(value1,
value2,
value3,
value4);这样即使你的表单中列的名字发生变化,语句还是能正常插入数据
更进一步
INSERT SELECT将数据添加到一个已经存在的表中
2
3
4
5
6
7
col2,
col3)
select(col1,
col2,
col3)
from table2;这样操作的前提是table1的结构于table2完全相同
假设某列不存在与table1中,这样操作无法将table2中某列完全复制到table1 中
CREATE SELECT将一个表的内容复制到一个全新的表当中
更新与删除数据
UPDATE更新数据表中某行的某些数据
2
3
set col1=***
where col* = ***;DELETE删除数据表中的某一行或者几行
2
where col* = ***;如果漏写了where子句,将会删除数据表中的每一行
而除了使用delete语句,使用turncate,drop语句也可以达到相同的效果
在这里贴上链接做一个记录
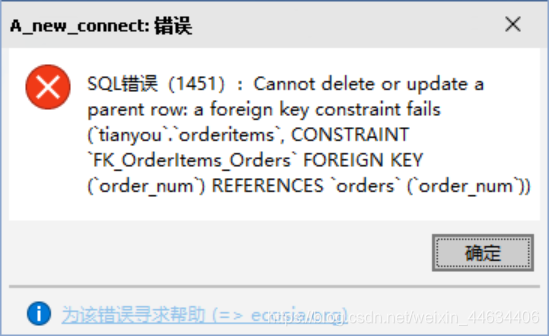
在删除数据时,如果删除的数据中的主键是另外某张表的外键,则会删除失败
如果坚持删除,需要将两张表中的数据一起删除,则会使用到联级删除
或者在定义外键时,对update和delete选项进行修改,直接改成CASCADE
Set NULL : Sets the column value to NULL when you delete the parent table row.
CASCADE : CASCADE will propagate the change when the parent changes. If you delete a row, rows in constrained tables that reference that row will also be deleted, etc.
RESTRICT : RESTRICT causes you can not delete a given parent row if a child row exists that references the value for that parent row.
NO ACTION : NO ACTION and RESTRICT are very much alike. when an UPDATE or DELETE statement is executed on the referenced table, the DBMS verifies at the end of the statement execution that none of the referential relationships are violated. in short child row no concern if parent row delete or update.这里还有一种办法
戳这里--------->外键唯一性检验CREATE TABLE
简单地把格式记录下俩
2
3
4
5
6
(
col1 int(4) not null,
col2 char(32) not null,
col3 char(50) not null
);ALTER TABLE
简单地自我熟悉下格式添加列
2
add col1 char(38);删除列
2
drop column col1;视图
视图的规则与限制
视图必须唯一命名
视图可以嵌套
创建视图必须拥有足够的权限一个最常见的视图的应用是隐藏复杂的sql,这些复杂的sql通常涉及到联结
下面来看下语句
2
3
4
5
select.......
from .......
where .......
;
今天早上你遇到一个问题
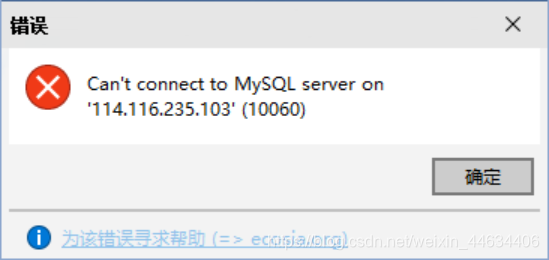
连不上服务器了好不出来
你决定登录自己的数据库
打开用户登陆界面你发现自己不知道密码,使用默认密码也登陆不上
失败码是10060
戳这里----->mysql无法连接10061问题
顺着链接里面介绍的操作你成功登录
但是空空如也没有数据
你要自己新建表单插入数据
戳这里-------->创建表单-create
戳这里-------->插入数据-populatebingo
存储过程
为什么你要使用存储过程?
通过将一系列复杂的操作封装在简单易用的单元中,每次执行相同操作时,只需要调用存储过程就可以完成复杂的工作。
为了对邮件发送清单中具有邮件地址的顾客进行计数,你想要构建一个简单的存储过程。
戳这里------->MySQL存储过程的基本语法
2
3
4
5
6
7
BEGIN
SELECT COUNT(*)
FROM customers
WHERE cust_email IS NOT NULL
INTO cnt;
END;
鉴于不同的数据库软件,你使用的语法也不尽相同,着手上网寻找问题的原因问题出在哪里呢?是没有在存储过程中declare变量吗?你不断地在心里问自己
该死,在添加上变量声明后,仍然报告错误
不一会儿,你已经尝试了各种办法(包括在变量前面添加@,删去end后面的分号,将into语句改成简单的等号,把第一行的out cnt int放在存储过程中),可问题始终没有解决
最后,你查阅了sql帮助手册
2
3
4
5
BEGIN
SELECT COUNT(*) INTO cities FROM world.city
WHERE CountryCode = country;
END//决定依葫芦画瓢修改自己的语句
2
3
4
5
6
BEGIN
SELECT COUNT(*) INTO cnt
FROM customers
WHERE cust_email IS NOT NULL;
END依然不行啊
难道是我select语句出错了吗?
可单独运行select语句时,一切正常,也给出了正确的计数结果
再次查看帮助
你发现
2
3
4
[DEFINER = user]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body根本不用加上begin和end(可能仅仅在存储过程中包含多个过程时,你才需要使用begin&end)
迷惑
2
3
4
5
SELECT COUNT(*) INTO cnt
FROM customers
WHERE cust_email IS NOT NULL;bingo
可谁又曾料想到,五天后你又遇到一个问题
上述存储过程只能存储一条语句,五天后的你想存储多条语句,这个时候仍然需要使用begin和end
2
3
4
5
6
7
8
BEGIN
SELECT *
FROM orders;
SELECT *
FROM orderitems;
END
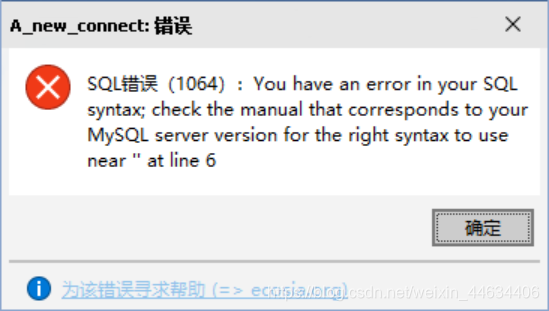
CALL p1();上诉代码仍然出错
你又去网上搜寻答案
在 MySQL 中,服务器处理 SQL 语句默认是以分号作为语句结束标志的。然而,在创建存储过程时,存储过程体可能包含有多条 SQL 语句,这些 SQL 语句如果仍以分号作为语句结束符,那么 MySQL 服务器在处理时会以遇到的第一条 SQL 语句结尾处的分号作为整个程序的结束符,而不再去处理存储过程体中后面的 SQL 语句,这样显然不行。
噢~
再次修改代码
2
3
4
5
6
7
8
9
CREATE PROCEDURE p1()
BEGIN
SELECT *
FROM orders;
SELECT *
FROM orderitems;
END //
CALL p1();bingo
好了现在你重新回到五天前的工作中如何调用这个存储过程?
按照网上的说法
你键入了一下代码
2
cnt = call mailingcountlist();失败,把返回值放在存储过程里面再试试
2
call mailingcountlist(cnt);失败,修改变量声明的方式
2
call mailingcountlist(@cnt);欧克,但还没做输出
2
3
call mailingcountlist(@cnt)
select @cnt;欧克
事务处理
戳这里了解------>MySQL事务,事务的基本概念,MySQL的基本事务处理
为什么要使用事务处理?使用事务处理(transaction processing),确保成批的sql操作,要么执行,要么完全不执行,来维护数据库的完整性
在使用事务处理时,有几个必须知道的关键词:
事务-transaction-指的是一组sql语句
回退-rollback-指的是撤销指定sql语句的过程
提交-commit-指的是将未存储的sql语句结果写入数据表库
保留点-save point-指的是事务处理中的设置的临时占位符-placeholder-可以对他发起回退事务处理用来管理insert,update,delete语句,不能回退select,create,drop操作
事务处理的语法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SAVEPOINT IN1; -- 每一个 rollback 都需要加上分号
INSERT INTO orders
VALUES(20011,
NULL,
'1000000004');
SAVEPOINT IN2; -- 如果已经 rollback to IN2,那就不能再rollback to IN3了
INSERT INTO orders
VALUES(20012,
NULL,
'1000000001');
SAVEPOINT IN3;
INSERT INTO orders
VALUES(20013,
NULL,
'1000000003');
ROLLBACK TO IN1; -- MySQL最后不需要再添加 commit transaction主键Primary Key
简单的陈列一些主键的性质:
任意两行的主键值各不相同
每行都具有一个主键值(不允许null)
包含主键值的列从来不会更新或者修改
主键值不能重用需要注意的是,每张表中都只能有一个主键
这一个主键可以是单独的一行,也可以是多行构成的联合主键外键Rerferences Key
外键是表中的一列,其值必须在另一表的主键中
外键可以保证引用的完整性下面举一个生动形象的例子:
Orders表中是录入到系统中的每个订单,Customers存储着所有的顾客信息
Orders表中的顾客ID与Customers表中的特定的顾客ID行相关联
顾客ID是Customer表中的主键在Orders表中顾客ID列上定义一个外键,该列只能接受Customers表中主键值
唯一约束
唯一约束用来保证一列或者是一组列中的数据是唯一的剩下的还有非空约束以及检查性约束
戳这里看五大约束------->数据库的五大约束wu
综上所述:这些约束可以保证数据库的安全性(防止误伤数据,避免数据库中数据出现重复或者遗漏)